
June 26, 2026
Building a General-Purpose Physical AI System for Food Manipulation (Part 3)
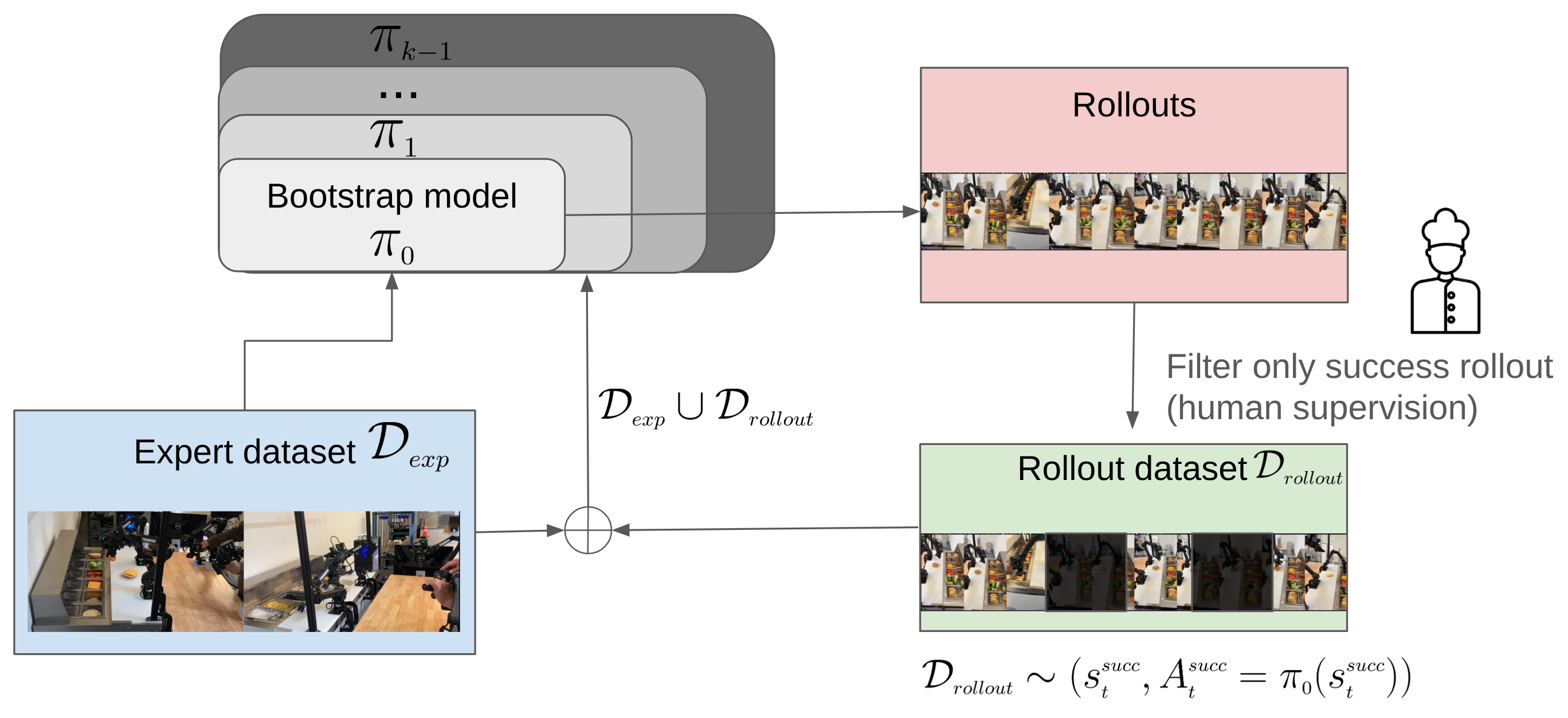
We’ve been teaching a physical AI system to assemble a burger in under a minute. Part 3 of our blog series explores how Chef’s data flywheel helped improve performance from 75% to 91.3% success rate with just 4.5% more training data.
Chef
Chef Robotics
Read More
%20copy.png)







