

Food pick consistency
Chef’s customers in food manufacturing care a lot about consistency. When assembling a meal that calls for, say, 50 g of mashed potatoes, it matters that each portion is as close to 50 g as possible. If it’s less, the consumer gets less than advertised; if it’s more, the manufacturer is giving away product at a loss.
We measure consistency using the coefficient of variation (CV), defined as the standard deviation divided by the mean (σ/μ). Our goal is to match or exceed human-level CV for the ingredients that Chef robots pick.
How Chef robots estimate pick weight today using volumetric pick depth
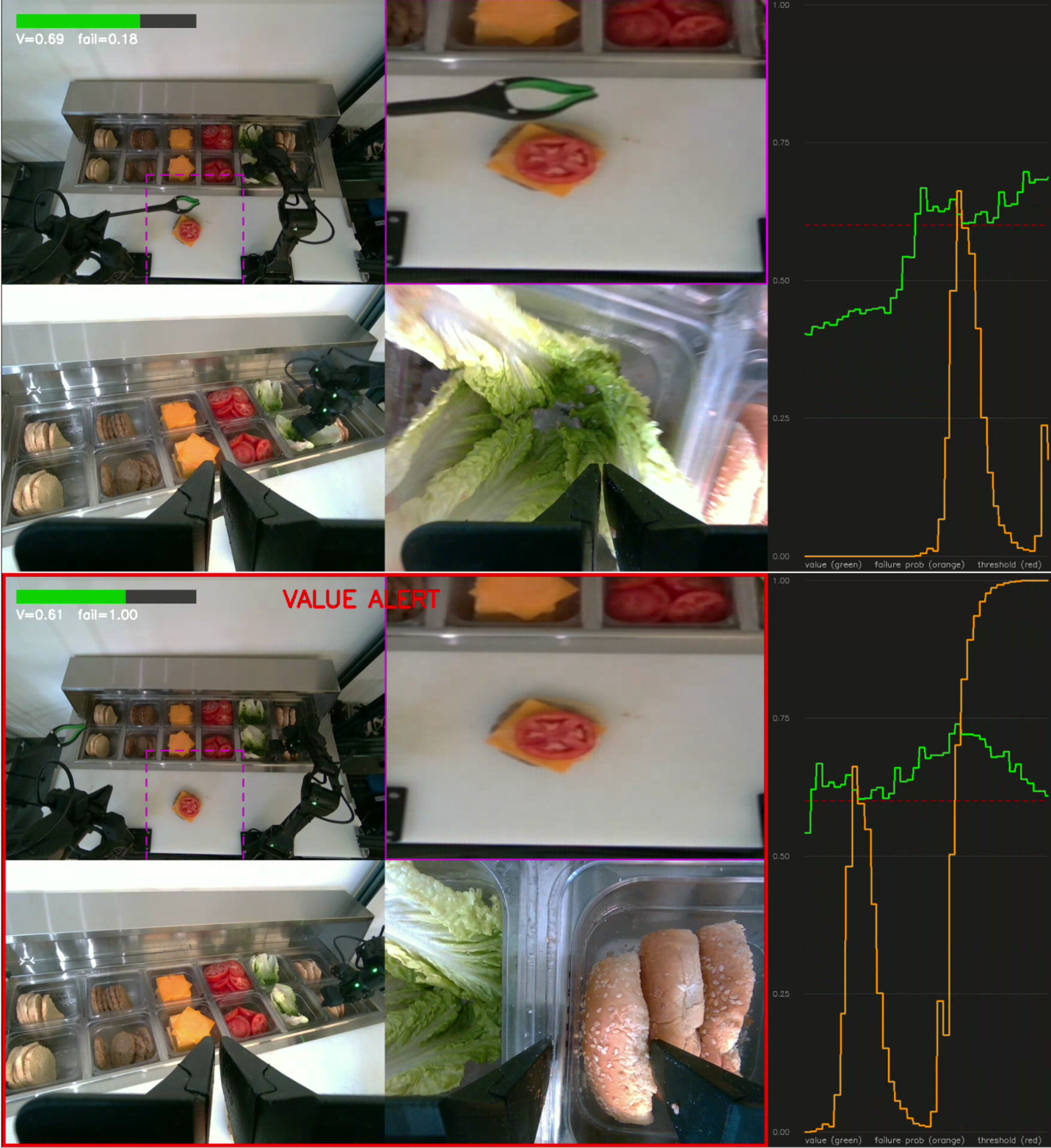
Picking exactly 50g of mashed potatoes every time is not straightforward. Chef robots use a depth camera to observe the ingredients in the pan and estimate where and how deep to insert the utensil.
Today, this estimation is based on a geometric model called volumetric pick depth (VPD). VPD computes the cross-sectional volume of the utensil at the point where it intersects the ingredient surface, then multiplies that volume by an estimated ingredient density to predict how much the utensil will pick at a given pick depth.
Because Chef robots sit above a high-accuracy scale, they can measure the weight of each pick directly by comparing the pan weight before and after the utensil lifts. Based on the difference between the expected and actual pick weight, the system adjusts its ingredient density estimate and corrects for the next pick. This feedback loop is called “autotune.”
VPD and autotune work well in production, delivering better-than-human consistency for most ingredients. But a purely geometric model has limits. It cannot account for what actually happens when a utensil interacts with food. For example, it does not anticipate ingredients overflowing out of the utensil during a pick, which can happen with certain ingredient types.

Looking at cases like these, we asked: could we use AI to build a more accurate model of ingredient interaction—one that learns directly from data rather than relying on geometric assumptions?
CLUTCH: a learned pick depth estimator
We developed an AI model called CLUTCH (computationally learn and understand topology-based clasp height).
CLUTCH is a neural network that takes two inputs: a point cloud of the ingredient surface captured by the depth camera and the target pick weight. From these, it outputs a recommended pick depth—how far the utensil should descend into the ingredient to hit the target weight.
A few notes on the architecture:
- Point cloud processing involves cropping and downsampling the raw depth data to a manageable representation of the ingredient surface.
- An MLP (multilayer perceptron, or fully connected network) processes the point cloud and the target weight together.
- Output format: Rather than treating pick depth as a continuous regression problem, we convert it to a classification problem over 1 mm bins. This allows us to use earth mover’s distance (EMD) loss, which penalizes predictions proportionally to how far they are from the correct bin — a natural fit for ordered outputs like depth.
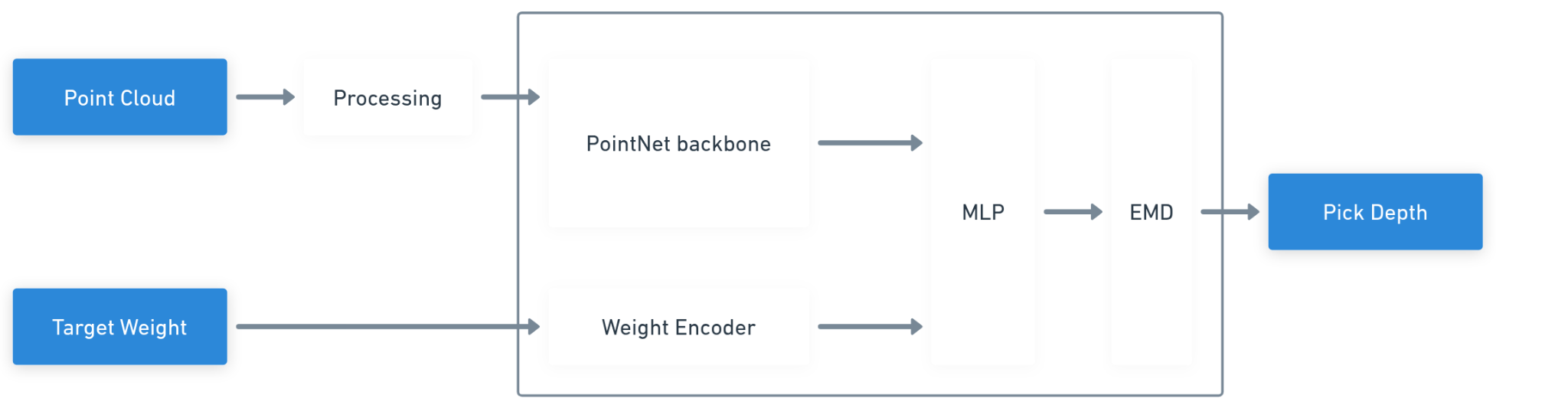
The pick depth is expressed relative to the point cloud’s mean z-value (height), so the model is not sensitive to absolute pan position.
How we collected training data
We configured Chef robots to continuously pick and dump dry rice between two pans, systematically varying the pick depth over a uniform range and measuring the resulting pick weight at each cycle. We used dry rice as the primary ingredient because its durability makes it well-suited for high-volume data collection, unlike fresh, cooked, or frozen ingredients, which degrade with repeated handling.
Results: CLUTCH vs. VPD
We compared CLUTCH and VPD across two test conditions: picking to a single fixed target weight repeatedly (the typical production scenario) and picking across a wide, randomly varying range of target weights (a harder, more general task).
Both models were evaluated offline on the same held-out dataset. In each test dataset, there is ground-truth ingredient surface topology, pick weight, and pick depth. None of this data was in the CLUTCH training set.
For VPD, we ran an offline optimization to find the ingredient-density input that minimized the mean absolute pick-depth error across the test set—an idealized version of autotune that could retroactively correct past picks. These VPD results therefore represent an upper bound on what VPD and autotune can achieve in practice.
CLUTCH results are raw model predictions with no additional correction applied.
We report results as “Z diff”—the difference in pick depth (i.e., utensil height) versus ground truth, measured in millimeters. The mean Z diff indicates directional bias; the standard deviation (std dev) of Z diff is a proxy for CV.
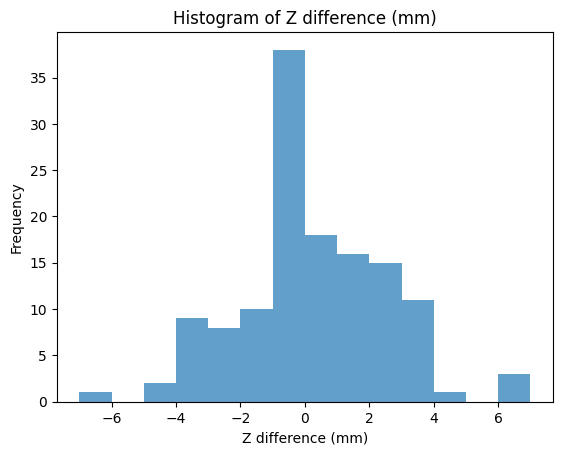
Single target weight (150 g)
At a single fixed target weight, VPD and CLUTCH perform comparably, with CLUTCH showing a modest improvement in the fraction of picks accurate within 2 mm.
VPD (offline optimized): 132 examples
- Mean z diff: 0.198 mm | Std dev: 2.428 mm
- Accurate within 0 mm: 17.42% | Accurate within 2 mm: 60.61% | Accurate within 5 mm: 96.21%
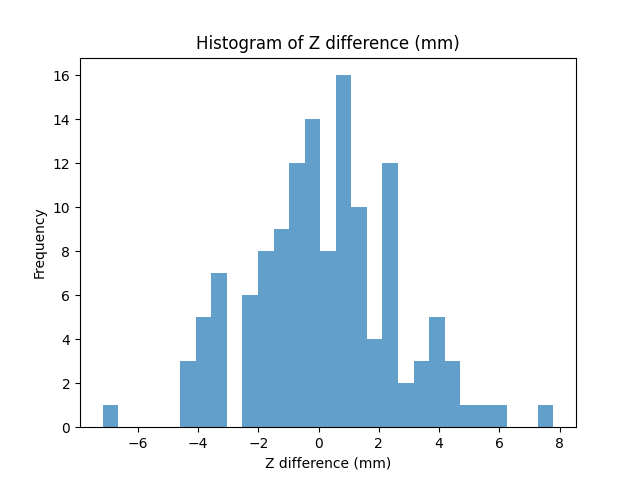
CLUTCH (raw): 132 examples
- Mean z diff: −0.242 mm | Std dev: 2.320 mm
- Accurate within 0 mm: 13.64% | Accurate within 2 mm: 73.48% | Accurate within 5 mm: 96.97%
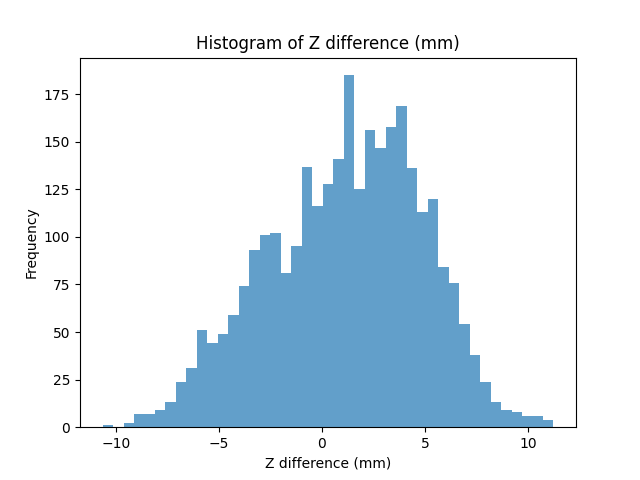
Random target weight
When the target weight varies widely, CLUTCH substantially outperforms VPD.
VPD (offline optimized): 2,996 examples
- Mean z diff: 1.154 mm | Std dev: 3.741 mm
- Accurate within 0 mm: 8.68% | Accurate within 2 mm: 32.94% | Accurate within 5 mm: 78.07%
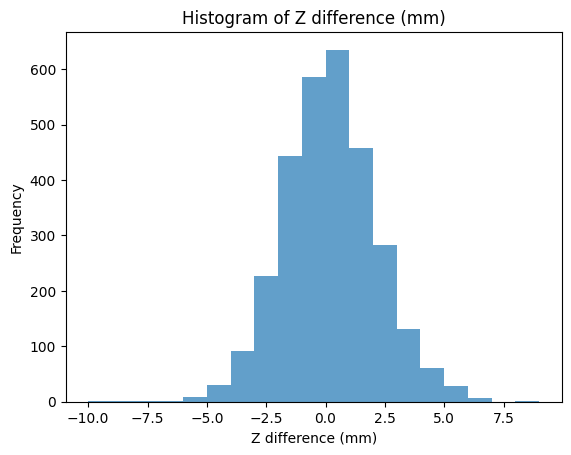
CLUTCH (raw): 2,995 examples
- Mean z diff: −0.305 mm | Std dev: 1.985 mm
- Accurate within 0 mm: 21.20% | Accurate within 2 mm: 80.27% | Accurate within 5 mm: 99.30%
What these results mean
Both VPD and CLUTCH are pick depth estimators: given an ingredient surface and a target weight, they predict how deep the utensil should go.
As a general estimator that works across arbitrary target weights, CLUTCH is clearly the stronger model. The results on the randomized test set show a roughly 2x reduction in the standard deviation of z diff and a more than 2x improvement in the fraction of picks accurate within 2 mm—without any closed-loop correction applied.
For production use cases where target weight is held constant and autotune continuously adjusts ingredient density over many picks, VPD’s and CLUTCH’s performance are much closer to parity. The geometric model performs significantly better when it can optimize to a fixed target.
The primary limitation of CLUTCH is that it requires training data for each combination of ingredients and utensils. VPD, by contrast, generalizes across utensil shapes and ingredient types without any training, though its geometric reasoning is less accurate; it requires no data collection to run on a new ingredient.
These early results show that AI-based food interaction models can achieve higher pick accuracy than geometric models without requiring closed-loop correction. As a next step, we plan to extend CLUTCH into a single, generalized food-interaction model trained on production data across Chef’s full range of utensils and ingredients.
Curious about how Chef robots handle ingredient variability in production, or want to follow along as we keep building? Get in touch with our team.

.jpg)