

The ingredient onboarding problem in food robotics
Food assembly robots don’t just need to know where an ingredient is. They need to know how that ingredient behaves when a utensil enters a pan, closes around it, lifts it, shakes it, moves it across a workspace, and releases it into a customer-specific container.
That makes generating robot trajectories, represented via a set of manipulation parameters, unusually hard.
For rigid objects, many pick-and-place systems can rely on a compact set of geometric and force parameters. Food is different. Rice, slaw, sauce, tortellini, ground meat, shredded cheese, and roasted vegetables each fail in different ways. Some ingredients compress tightly into a robotic utensil. Some hold the utensil open, causing spillage. Some drip from or stick to the utensil. The robot’s planner needs to handle all of these potential behaviors.
In practice, a production manipulation configuration can include dozens of parameters: utensil type, pick depth, pick “jiggle” count and amplitude, placement height, release timing, “post-pick shake” behavior, and more. These parameters aren’t independent. A change that improves weight consistency can slow down cycle time. A lower placement height can improve presentation in one tray but create collision risk in another. A utensil that works well for cooked rice may be inappropriate for individually quick-frozen (IQF) rice, even though the raw ingredient is the same.
Historically, onboarding a new ingredient has required Chef’s applications engineering team to reason through the above factors step-by-step. Our applications engineers look at new ingredients and utilize their expertise in food manipulation, understanding of customer requirements, and Chef robot system details to guess the utensil and manipulation software parameters they think are most likely to work with the new ingredient. They then test their assumptions, observe how the ingredients perform in production, and iterate. This process works, but it’s time-consuming, expertise-heavy, and difficult to scale as the number of ingredients on our platform grows.
Utensil selection is its own challenge
Before configuring the robot’s planner for a new ingredient, choosing the right utensil can be challenging in itself.
Chef robots use a family of utensils designed for different ingredient behaviors and target weights. The A and B series are “volumetric” utensils, with different internal volumes for packing solid ingredients as consistently as possible. The C series is used for “non-volumetric” ingredients such as sauces, sticky mashes, cheeses, and ground meats, where clean release matters more than tight packing. Special stew-oriented utensils handle liquids with large chunks that can prevent ordinary utensils from closing.
The best utensil is not simply one that can hold the target weight. In many cases, the goal is the smallest utensil that reliably fits the deposit. Too large, and the food doesn’t pack consistently. Too small, and the utensil may fail to close or pick properly. The correct answer depends on target weight, density, compressibility, particle size, stickiness, as well as the container used for placement. The best way to determine this is often to look for similar ingredients that have performed well in production.
This combination of physical judgment and historical comparison made both utensil and manipulation parameter selection a natural target for modern AI techniques.
Using embeddings to find similar ingredients
To solve the ingredient onboarding problem, we kicked off a project called “SAGE” (the similarity-based autological guidance engine). We wanted to build a system that could look at new ingredients (e.g., an image, description, and other inputs), compare those against ingredients our robots are already handling in production, and use this data to recommend the best utensil and manipulation parameters to use with the new ingredient.
Our first idea for a baseline system was one that would compare image and text embeddings of new ingredients against existing ingredients. Embeddings are vectors extracted from foundation models (we used CLIP) used to quantitatively compare similarity between images or strings of text. The idea was simple: if we’re onboarding a new type of pasta, we might be able to use the same utensil and manipulation parameters as those we already use for another type of pasta that’s performing well in production.
Unfortunately, this idea didn’t work well in practice. Food images and strings that appear similar to a generic model trained for image classification and captioning tasks may not actually be similar in terms of how our robots should manipulate those ingredients.
For example, can you guess what food this is?

These are small pancakes. From our existing production data, CLIP found the closest ingredient (based on image similarity) to be IQF apples. As you can imagine, the ideal utensil and manipulation parameters for pancakes and frozen apples would be quite different.
We also tried a weighted combination of image and text similarity, but this approach didn’t result in much improvement, especially when there were no great production analogs (i.e., strong real-world matches in our production data) for the given new ingredient.
Teaching LLMs about food manipulation
To improve on this baseline system, which was built around the idea of finding the closest ingredient in production that looks and sounds similar to the one we’re onboarding, we realized we needed to encode far more context around food manipulation. Large language models (LLMs) are appropriate for this, especially as long context windows allow us to include a significant amount of information in their prompt without the need for fine-tuning. We found we were able to distill our knowledge of utensil and manipulation parameter selection into “user manuals” for the LLM (we used GPT-5 on the OpenAI platform). OpenAI’s tool use API also allowed us to encode agentic behavior, allowing GPT-5 to do things like querying for production images to confirm assumptions about ingredient properties while reasoning through its utensil and manipulation parameter recommendations.
To onboard a new ingredient, we also need more than an ingredient image and name. We input the name, an optional long-form description, target weight (how many grams the robot needs to pick), customer name, container type, placement region in the container, and robot utensil configuration (single vs. multiple utensils on the robot). The image is now optional, as a lot of reasoning happens from the above input alone, and we found that a freeform description, e.g., “these are very sticky mashed potatoes” or “high throughput is important to me” can be very valuable in improving the recommendation and guiding it toward customer requirements. The customer and container information are useful for determining placement parameters and for prioritizing matching against ingredients used by the same customer, as different customers often have different preferences and requirements.
We experimented with our utensil and manipulation parameter selection guides, encoding of inputs, reasoning flow, and production data queries to develop an agentic AI system that is effective at recommending utensils and manipulation parameters.
How SAGE works
SAGE is implemented as an LLM agent that starts with a target foodstuff profile consisting of the inputs above. The profile includes the information an engineer would normally use when reasoning about a new ingredient: what it’s called, how it’s described, what it looks like, how much must be deposited, what container it goes into, and which utensil slots are available on the robot.
The agent then compares this profile against a production reference library. The reference data includes prior ingredients, target weights, utensils, existing manipulation parameters, and performance signals such as coefficient of variation, active cycle time, protective-stop rate, total deposit count, and most recent production date.
The reasoning workflow has four main steps:
1. Classify the ingredient
SAGE first classifies the ingredient into a handling category. Non-volumetric ingredients include sauces, liquids, ground or squishy meats, sticky mashes, cheeses, and stews. Volumetric ingredients are organized into density and compressibility bands, from IQF large particulates all the way to soft-cooked grains.
This classification matters because it determines which utensil families are viable and which reference deposits should be trusted. For example, cooked rice and IQF rice should not be treated as interchangeable, even if both are “rice.” Their density and compressibility lead to vastly different utensil and parameter choices - another example of food manipulation nuance that ordinary similarity matching would miss.
2. Select a utensil from production analogs
For utensil recommendation, SAGE looks for production deposits with a similar ingredient class and nearby target weight. It prioritizes ingredient behavior first, then deposit weight, then exact ingredient similarity, confidence, production performance, and customer context.
For volumetric utensils, SAGE uses a sizing rule: start from the closest reference utensil, then check whether that utensil has successfully deposited a higher-weight ingredient at equal or lower density. If not, size up. If it does fit but is likely oversized, size down to the smallest utensil that still has production evidence for fitting the new deposit.
For non-volumetric utensils, SAGE checks whether the target weight falls within the historical operating range for that utensil family and size.
3. Build reference sets for parameters
A single nearest neighbor is rarely enough. Different parameters should be copied or inferred from different kinds of references.
SAGE builds several reference sets:
- Ingredient analogs for parameters that depend highly on their physical characteristics, e.g., pick “jiggles” or post-pick “shakes”
- Same-utensil references for parameters that depend strongly on the selected utensil, such as maximum pick-depth overrides
- Placement-context references for customer, bowl, region, translation, rotation, entrance height, and placement height
- Multi-deposit timing references for robots configured with multiple occupied utensil slots
This mirrors how an experienced engineer reasons. One ingredient may be the best analog for physical behavior, while another may be the best analog for placement into a specific tray region.
4. Source parameters from references; apply reasoning and constraints
After building the reference sets and copying parameters from the appropriate references, the agent also reasons about cases like conflicting references or lack of good analogs, in which case it falls back to sensible defaults.
The output is also constrained; numerical parameters have explicit bounds. Certain parameters are coupled, such as placement rotation and pick-target rotation. These checks keep the recommendation in the space of configurations that the robot can actually execute. A final config schema check ensures that the manipulation parameters will run on the robot.
We also log the verbal reasoning flow and reference sets. This makes the recommendation traceable and debuggable, allowing us to improve our prompts and data.
Why LLM agents solve ingredient onboarding
SAGE sits in a useful middle ground between pure rules and end-to-end model training.
The problem has structure: there are known utensil families, known parameter ranges, known constraints, known customer and container contexts, and a large set of historical production examples. But the problem also requires qualitative, “fuzzy” reasoning: recognizing that one ingredient is sticky, another is IQF, another hangs during placement, and another behaves like a sauce even if its name is ambiguous.
An LLM agent can combine these two modes. The prompt encodes Chef’s expert heuristics derived from years of food manipulation knowledge. The production dataset provides concrete evidence. Tool calls let the model inspect reference ingredients. When the system makes a poor recommendation, the team can inspect the conversation trace, update the prompt, add better reference data, or adjust the constraints without retraining a model from scratch.
That makes the system auditable and iterative, which is valuable for robotics work where recommendations eventually affect physical machines.
Measuring results
When SAGE recommends utensils and manipulation parameters, how do we know they are good recommendations?
We evaluate SAGE similarly to a supervised machine-learning system. First, we create a dataset of ingredients run in production by Chef’s robot fleet. Ingredients must meet minimum production recency, production volume, and performance requirements to ensure recommendation quality. We then split this dataset into train and test sets. The training set becomes the in-prompt reference library. Test ingredients are held out, then treated as new ingredients for SAGE to recommend against. The ground truth is the active production configuration for the held-out ingredient and target weight.
For manipulation parameters, we measure a metric called Num Param Diffs (NPD). NPD counts how many output parameters differ on average between SAGE’s prediction and a known “ground-truth” production config that performs well. Numerical parameters count as different when they differ by more than a conservative tolerance threshold. Categorical parameters count as different when they don’t match exactly.
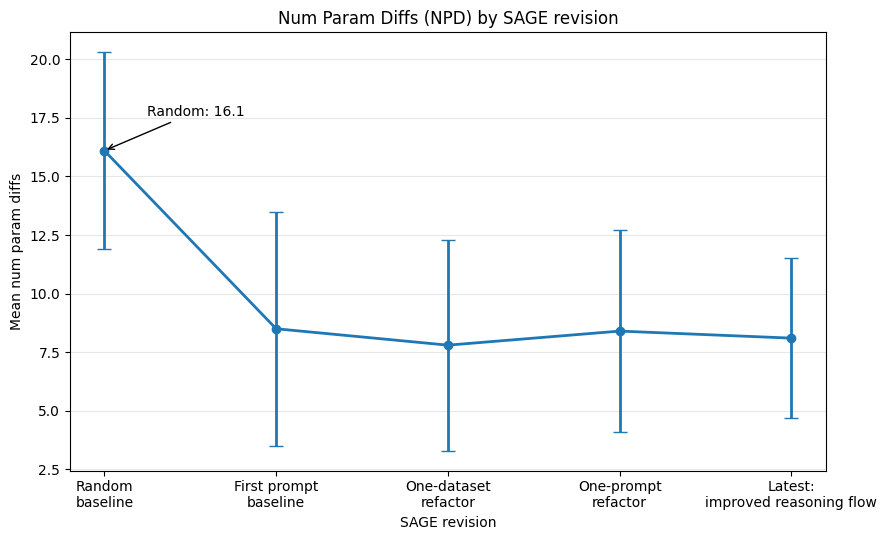
We track NPD across SAGE refactors and revisions and compare results to a baseline random prediction. All SAGE revisions perform much better than random, and the latest improvements to reasoning reduce NPD standard deviation as well.
Utensil selection is measured separately because it’s a discrete, high-leverage decision. SAGE returns a ranked top-three recommendation, so we track top-1, top-2, and top-3 match rates against the production utensil. We also track utensil-class match rate, since choosing the right family but an adjacent size is easier to recover from than choosing the wrong family entirely. The latest SAGE version achieves 100% top-3 accuracy for utensil prediction (both family and size) in the test set.
Neither metric is perfect - we don’t achieve 100% prediction accuracy against ground truth. This is expected, as there are often many valid solutions that are near-optimal but quite different in their composition. For example, we have observed that it’s possible to get two different utensils (with different manipulation parameters) to run well in production. But the benchmark is useful as a directional comparison.
The benchmark also produces diagnostic outputs. By ranking which parameters are missed most often, the team can see where the prompt or reference data needs more guidance, or where the prediction could be valid even if it doesn’t match ground truth.
When deployed in production, we don’t use a heldout set for SAGE; we might as well use all the data we have as a reference for new ingredients. And as Chef robots produce more ingredients for more customers, we add to our reference dataset, and SAGE naturally improves over time.
Ingredient onboarding is a fundamentally messy, real-world problem, but with the right combination of structured data, production feedback, and LLM-based reasoning, it becomes tractable at scale. And this is just the beginning: ingredient onboarding is one piece of a larger shift toward physical AI systems that can reason, adapt, and improve in real-world food environments.
If that excites you, we’re hiring.
.jpg)
%20copy.png)